Mozart: Modularized and Efficient MoE Training on 3.5D Wafer-Scale Chiplet Architectures
By Shuqing Luo 1, Han Ye 2, Pingzhi Li 1, Jiayin Qin 2, Jie Peng 1, Yang (Katie) Zhao 2, Yu (Kevin) Cao 2, Tianlong Chen 1
1 University of North Carolina at Chapel Hill
2 University of Minnesota - Twin Cities
Abstract
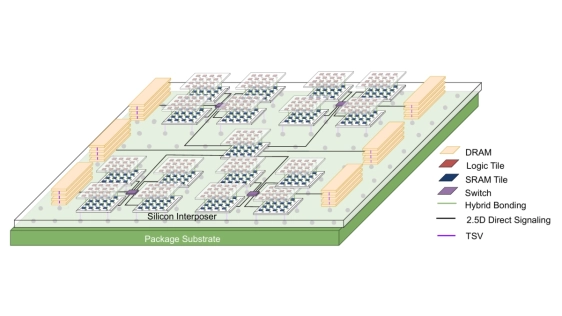
Mixture-of-Experts (MoE) architecture offers enhanced efficiency for Large Language Models (LLMs) with modularized computation, yet its inherent sparsity poses significant hardware deployment challenges, including memory locality issues, communication overhead, and inefficient computing resource utilization. Inspired by the modular organization of the human brain, we propose Mozart, a novel algorithm-hardware co-design framework tailored for efficient training of MoE-based LLMs on 3.5D wafer-scale chiplet architectures. On the algorithm side, Mozart exploits the inherent modularity of chiplets and introduces: (1) an expert allocation strategy that enables efficient on-package all-to-all communication, and (2) a fine-grained scheduling mechanism that improves communication-computation overlap through streaming tokens and experts. On the architecture side, Mozart adaptively co-locates heterogeneous modules on specialized chiplets with a 2.5D NoP-Tree topology and hierarchical memory structure. Evaluation across three popular MoE models demonstrates significant efficiency gains, enabling more effective parallelization and resource utilization for large-scale modularized MoE-LLMs.
To read the full article, click here
Related Chiplet
- DPIQ Tx PICs
- IMDD Tx PICs
- Near-Packaged Optics (NPO) Chiplet Solution
- High Performance Droplet
- Interconnect Chiplet
Related Technical Papers
- The Revolution of Chiplet Technology in Automotive Electronics and Its Impact on the Supply Chain
- Hecaton: Training and Finetuning Large Language Models with Scalable Chiplet Systems
- Towards Future Microsystems: Dynamic Validation and Simulation in Chiplet Architectures
- 3D-ICE 4.0: Accurate and efficient thermal modeling for 2.5D/3D heterogeneous chiplet systems
Latest Technical Papers
- Affinity Tailor: Dynamic Locality-Aware Scheduling at Scale
- AMMA: A Multi-Chiplet Memory-Centric Architecture for Low-Latency 1M Context Attention Serving
- Exploring the Efficiency of 3D-Stacked AI Chip Architecture for LLM Inference with Voxel
- Epoxy Composites Reinforced with Long Al₂O₃ Nanowires for Enhanced Thermal Management in Advanced Semiconductor Packaging
- Chipmunq: A Fault-Tolerant Compiler for Chiplet Quantum Architectures