Exploring the Efficiency of 3D-Stacked AI Chip Architecture for LLM Inference with Voxel
By Yiqi Liu, Noelle Crawford, Michael Wang, Jilong Xue, Jian Huang
University of Illinois Urbana-Champaign
Abstract
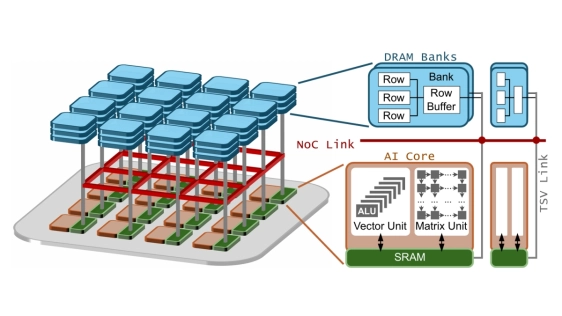
To overcome the well-known memory bottleneck of AI chips, 3D stacked architectures that employ advanced packaging technology with high-density through-silicon vias (TSVs) pins have proven to be a promising solution. The 3D-stacked AI chip enables ultra-high memory bandwidth between compute and memory by stacking numerous DRAM banks atop many AI cores in a distributed manner. However, it is not easy to explore the efficiency of the 3D-stacked AI chip, due to its unique distributed nature. And we need to carefully consider multiple intertwined factors that range from upper-level computing paradigm to machine learning (ML) compiler optimizations, and to the underlying hardware architecture.
In this paper, we develop Voxel, a fast and compiler-aware end-to-end simulation framework to facilitate exploring the efficiency of 3D-stacked AI chips for large language model (LLM) inference. Voxel enables the software/hardware co-exploration by employing a programming interface that allows ML compilers to customize the model execution plans. After validating the results of Voxel with an emulator on real silicon, we thoroughly examine the impact and correlation of different aspects of 3D-stacked AI chips, including state-of-the-art compute paradigms, tile-to-core mapping, tensor-to-bank mapping, NoC topologies and link bandwidth, DRAM bank bandwidth, per-core SRAM capacity, and energy/thermal constraints. Our findings disclose that the end-to-end efficiency of a 3D stacked AI chip not only is determined by the cooperative function of these factors, but also significantly depends on the mappings from tiles to AI core and DRAM banks. We report our findings throughout the paper, with the expectation that they will shed light on the development of the 3D-stacked AI chip ecosystem. We will open source Voxel and our study results for public research.
To read the full article, click here
Related Chiplet
- DPIQ Tx PICs
- IMDD Tx PICs
- Near-Packaged Optics (NPO) Chiplet Solution
- High Performance Droplet
- Interconnect Chiplet
Related Technical Papers
- Cambricon-LLM: A Chiplet-Based Hybrid Architecture for On-Device Inference of 70B LLM
- Chiplets Are The New Baseline for AI Inference Chips
- PICNIC: Silicon Photonic Interconnected Chiplets with Computational Network and In-memory Computing for LLM Inference Acceleration
- ChipLight: Cross-Layer Optimization of Chiplet Design with Optical Interconnects for LLM Training
Latest Technical Papers
- AMMA: A Multi-Chiplet Memory-Centric Architecture for Low-Latency 1M Context Attention Serving
- Exploring the Efficiency of 3D-Stacked AI Chip Architecture for LLM Inference with Voxel
- Epoxy Composites Reinforced with Long Al₂O₃ Nanowires for Enhanced Thermal Management in Advanced Semiconductor Packaging
- Chipmunq: A Fault-Tolerant Compiler for Chiplet Quantum Architectures
- Cross Waveguide Design for Color-Centers in Diamond for Photonic Quantum Computing