Affinity Tailor: Dynamic Locality-Aware Scheduling at Scale
By Jin Xin Ng, Ori Livneh, Richard O'Grady, Josh Don, Peng Ding, Samuel Grossman, Luis Otero, Chris Kennelly, David Lo, Carlos Villavieja
Google, USA
Abstract
Modern large multicore systems often run multiple workloads that share CPUs under schedulers such as Linux CFS. To keep CPUs busy, these schedulers load-balance runnable work, causing each workload to execute on many cores. This weakens locality at the microarchitectural level: workloads lose reuse in caches, branch predictors, and prefetchers, and interfere more with one another - especially on chiplet-based systems, where spreading execution across cores also spreads it across LLC boundaries. A natural alternative is strict CPU partitioning, but hard partitions leave capacity idle when workloads do not fully use their reserved CPUs.
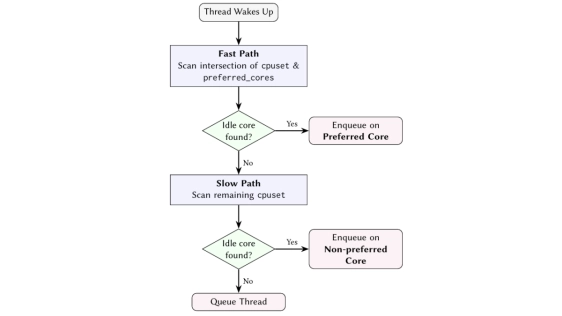
We present Affinity Tailor, a userspace-guided kernel scheduling system built on a key insight: the kernel can preserve locality for workloads that share CPUs by treating demand-sized, topologically compact CPU sets as affinity hints rather than hard partitions. A userspace controller estimates each workload's CPU demand online and assigns a preferred CPU set sized to that demand, chosen to be as disjoint as possible from other workloads while spanning as few LLC domains as possible. The kernel then uses this set as an affinity hint, steering threads toward those CPUs while still allowing execution elsewhere when needed to preserve utilization. Deployed at Google, Affinity Tailor delivers geometric-mean per-CPU throughput gains of 12% on chiplet-based systems and 3% on non-chiplet systems over Linux CFS. Furthermore, faster execution reduces memory residency, yielding per-GB throughput gains of 3-7%. Our findings suggest that future schedulers should treat spatial locality as a first-class objective, even at the expense of work-conservation.
To read the full article, click here
Related Chiplet
- DPIQ Tx PICs
- IMDD Tx PICs
- Near-Packaged Optics (NPO) Chiplet Solution
- High Performance Droplet
- Interconnect Chiplet
Related Technical Papers
- Expert Streaming: Accelerating Low-Batch MoE Inference via Multi-chiplet Architecture and Dynamic Expert Trajectory Scheduling
- Inter-Layer Scheduling Space Exploration for Multi-model Inference on Heterogeneous Chiplets
- SCAR: Scheduling Multi-Model AI Workloads on Heterogeneous Multi-Chiplet Module Accelerators
- ARCAS: Adaptive Runtime System for Chiplet-Aware Scheduling
Latest Technical Papers
- Affinity Tailor: Dynamic Locality-Aware Scheduling at Scale
- AMMA: A Multi-Chiplet Memory-Centric Architecture for Low-Latency 1M Context Attention Serving
- Exploring the Efficiency of 3D-Stacked AI Chip Architecture for LLM Inference with Voxel
- Epoxy Composites Reinforced with Long Al₂O₃ Nanowires for Enhanced Thermal Management in Advanced Semiconductor Packaging
- Chipmunq: A Fault-Tolerant Compiler for Chiplet Quantum Architectures