LEXI: Lossless Exponent Coding for Efficient Inter-Chiplet Communication in Hybrid LLMs
By Miao Sun, Alish Kanani, Kaushik Shroff, and Umit Ogras
Department of Electrical and Computer Engineering, University of Wisconsin-Madison
Abstract
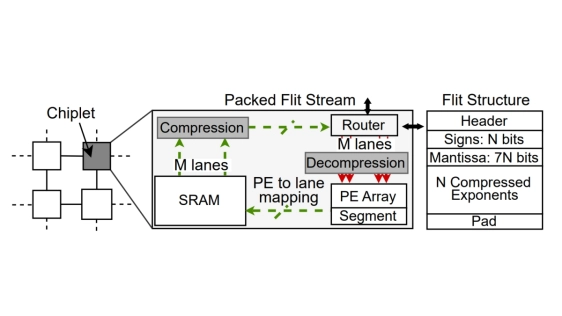
Data movement overheads increase the inference latency of state-of-the-art large language models (LLMs). These models commonly use the bfloat16 (BF16) format for stable training. Floating-point standards allocate eight bits to the exponent, but our profiling reveals that exponent streams exhibit fewer than 3 bits Shannon entropy, indicating high inherent compressibility. To exploit this potential, we propose LEXI, a novel lossless exponent compression scheme based on Huffman coding. LEXI compresses activations and caches on the fly while storing compressed weights for just-in-time decompression near compute, without sacrificing system throughput and model accuracy. The codecs at the ingress and egress ports of network-on-chip routers sustain the maximum link bandwidth via multi-lane LUT decoders, incurring only 0.09 percent area and energy overheads with GF 22 nm technology. LEXI reduces inter-chiplet communication and end-to-end inference latencies by 33-45 percent and 30-35 percent on modern Jamba, Zamba, and Qwen LLMs implemented on a homogeneous chiplet architecture.
To read the full article, click here
Related Chiplet
- DPIQ Tx PICs
- IMDD Tx PICs
- Near-Packaged Optics (NPO) Chiplet Solution
- High Performance Droplet
- Interconnect Chiplet
Related Technical Papers
- MCMComm: Hardware-Software Co-Optimization for End-to-End Communication in Multi-Chip-Modules
- DeepOHeat-v1: Efficient Operator Learning for Fast and Trustworthy Thermal Simulation and Optimization in 3D-IC Design
- Leveraging Chiplet-Locality for Efficient Memory Mapping in Multi-Chip Module GPUs
- Probing the Nanoscale Onset of Plasticity in Electroplated Copper for Hybrid Bonding Structures via Multimodal Atomic Force Microscopy
Latest Technical Papers
- Affinity Tailor: Dynamic Locality-Aware Scheduling at Scale
- AMMA: A Multi-Chiplet Memory-Centric Architecture for Low-Latency 1M Context Attention Serving
- Exploring the Efficiency of 3D-Stacked AI Chip Architecture for LLM Inference with Voxel
- Epoxy Composites Reinforced with Long Al₂O₃ Nanowires for Enhanced Thermal Management in Advanced Semiconductor Packaging
- Chipmunq: A Fault-Tolerant Compiler for Chiplet Quantum Architectures