DeepStack: Scalable and Accurate Design Space Exploration for Distributed 3D-Stacked AI Accelerators
By Zhiwen Mo 1, Guoyu Li 1, Hao (Mark) Chen 1, Yu Cheng 2, Zhengju Tang 2, Qianzhou Wang 1, Lei Wang 2, Shuang Liang 1, Lingxiao Ma 3, Xianqi Zhou 3, Yuxiao Guo 3, Wayne Luk 1, Jilong Xue 3, Hongxiang Fan 1
1 Imperial College London,
2 Peking University,
3 Tile-AI
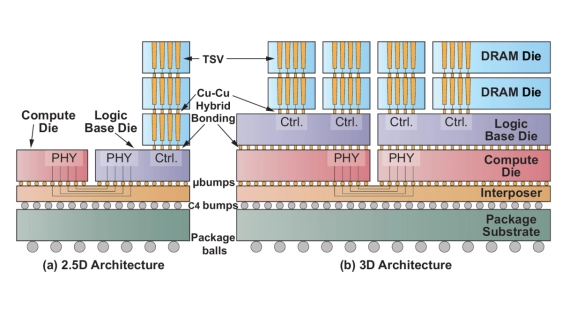
Abstract
Advances in hybrid bonding and packaging have driven growing interest in 3D DRAM-stacked accelerators with higher memory bandwidth and capacity. As LLMs scale to hundreds of billions or trillions of parameters, distributed inference across multiple 3D chips becomes essential. With cross-stack co-design increasingly critical, we propose DeepStack, an accurate and efficient performance model and tool to enable early-stage system-hardware co-design space exploration (DSE) for distributed 3D-stacked AI systems. At the hardware level, DeepStack captures fine-grained 3D memory semantics such as transaction-aware bandwidth, bank activation constraints, buffering limitations, and thermal-power modeling. At the system level, DeepStack incorporates comprehensive parallelization strategies and execution scheduling for distributed LLM inference. With novel modeling techniques such as dual-stage network abstraction and tile-level compute-communication overlap, we achieve up to 100,000x faster runtime over state-of-the-art simulators at comparable accuracy, cross-validated against our in-house 3D designs, NS-3 backend (2.12%), and vLLM serving on 8xB200 GPUs (12.18%). With hierarchical design space search, DeepStack enables efficient exploration over 2.5x10^14 design points spanning 3D-stacked DRAM layers, DRAM vertical connectivity, interconnect, compute-memory allocation, and distributed scheduling. Compared with baseline designs, DeepStack achieves up to 9.5x higher throughput through co-optimized parallelism and 3D architecture search. Our DSE further reveals that batch size drives a more fundamental architectural divide than the prefill/decode distinction, and that parallelism strategy and hardware architecture are tightly coupled -- incomplete schedule search leads to permanently suboptimal silicon irrecoverable by software tuning. We intend to open source DeepStack to support future research.
To read the full article, click here
Related Chiplet
- DPIQ Tx PICs
- IMDD Tx PICs
- Near-Packaged Optics (NPO) Chiplet Solution
- High Performance Droplet
- Interconnect Chiplet
Related Technical Papers
- ATSim: A Fast and Accurate Simulation Framework for 2.5D/3D Chiplet Thermal Design Optimization
- Compass: Mapping Space Exploration for Multi-Chiplet Accelerators Targeting LLM Inference Serving Workloads
- Mapping Space Exploration for Multi-Chiplet Accelerators Targeting LLM Inference Serving Workloads
- RapidChiplet: A Toolchain for Rapid Design Space Exploration of Chiplet Architectures
Latest Technical Papers
- DeepStack: Scalable and Accurate Design Space Exploration for Distributed 3D-Stacked AI Accelerators
- Mapping Space Exploration for Multi-Chiplet Accelerators Targeting LLM Inference Serving Workloads
- Escaping Flatland: A Placement Flow for Enabling 3D FPGAs
- 3D optoelectronics and co-packaged optics: when solving the wrong problems stalls deployment
- Expert Streaming: Accelerating Low-Batch MoE Inference via Multi-chiplet Architecture and Dynamic Expert Trajectory Scheduling