A PPA-Driven 3D-IC Partitioning Selection Framework with Surrogate Models
By Shang Wang 1, Shuai Liu 1, Owen Randall 1, Matthew E. Taylor 1,2
1 University of Alberta, Canada
2 Alberta Machine Intelligence Institute (Amii), Canada
Abstract
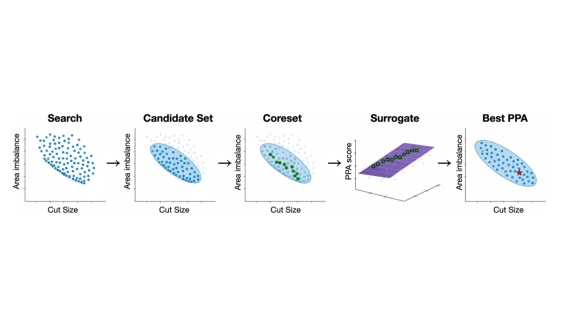
3D-IC netlist partitioning is commonly optimized using proxy objectives, while final PPA is treated as a costly evaluation rather than an optimization signal. This proxy-driven paradigm makes it difficult to reliably translate additional PPA evaluations into better PPA outcomes. To bridge this gap, we present DOPP (D-Optimal PPA-driven partitioning selection), an approach that bridges the gap between proxies and true PPA metrics. Across eight 3D-IC designs, our framework improves PPA over Open3DBench (average relative improvements of 9.99% congestion, 7.87% routed wirelength, 7.75% WNS, 21.85% TNS, and 1.18% power). Compared with exhaustive evaluation over the full candidate set, DOPP achieves comparable best-found PPA while evaluating only a small fraction of candidates, sub stantially reducing evaluation cost. By parallelizing evaluations, our method delivers these gains while maintaining wall-clock runtime comparable to traditional baselines.
Index Terms — 3D IC Partitioning, Linear regression, D-optimal design, Power Performance Area (PPA)
To read the full article, click here
Related Chiplet
- DPIQ Tx PICs
- IMDD Tx PICs
- Near-Packaged Optics (NPO) Chiplet Solution
- High Performance Droplet
- Interconnect Chiplet
Related Technical Papers
- WarPGNN: A Parametric Thermal Warpage Analysis Framework with Physics-aware Graph Neural Network
- Fulfilling 3D-IC Trade-Off Analyses (And Benefits) With An AI Assist
- A Heterogeneous Chiplet Architecture for Accelerating End-to-End Transformer Models
- The 3D-IC Multiphysics Challenge Dictates A Shift-Left Strategy
Latest Technical Papers
- CHICO-Agent: An LLM Agent for the Cross-layer Optimization of 2.5D and 3D Chiplet-based Systems
- A PPA-Driven 3D-IC Partitioning Selection Framework with Surrogate Models
- Fleet: Hierarchical Task-based Abstraction for Megakernels on Multi-Die GPUs
- ChipLight: Cross-Layer Optimization of Chiplet Design with Optical Interconnects for LLM Training
- ELMoE-3D: Leveraging Intrinsic Elasticity of MoE for Hybrid-Bonding-Enabled Self-Speculative Decoding in On-Premises Serving